
Estimating AI costs sounds simple until you actually try to do it. At first it feels like basic math: check a model's pricing page, estimate how many tokens you'll use, multiply a few numbers together, and assume you've got a reasonable forecast. In reality, it rarely works that way.
One calculator gives you one estimate, another gives you a completely different result, and when real users start interacting with your product, the actual bill often lands somewhere else entirely. After building AI-powered products across providers like OpenAI, Anthropic, Gemini, DeepSeek, Groq, and OpenRouter, I've learned that the biggest challenge usually isn't model pricing — it's token estimation. And if your token estimates are wrong, every cost projection built on top of them is wrong too.
That's why choosing the right AI token cost calculator matters more than most people realize.
What Surprised Me Most About AI Costs
When I first started building AI-powered products, I assumed model pricing would be the biggest factor affecting costs, so I spent most of my time comparing providers. Should I use OpenAI? Would Claude be worth the premium? Could DeepSeek deliver similar results for less money? Like many builders, I focused heavily on pricing pages and cost-per-token charts.
What surprised me was that token estimation created bigger problems than pricing itself. I remember using DeepSeek for what I considered a relatively small task. DeepSeek is widely known for being affordable, yet the final bill still came in higher than I expected. The model wasn't expensive — my assumptions about token usage were simply wrong. Once conversation history, larger prompts, additional context, and repeated requests started piling up, the real usage looked nothing like my original estimate.
That experience changed how I approach AI projects. Now, before shipping any AI feature, I try to estimate costs first, because inaccurate assumptions feed straight into pricing, profitability, and long-term sustainability.
Why Most AI Cost Calculators Get It Wrong
Most AI cost calculators follow the same premise: estimate token usage, multiply by model pricing, display the result. That works for a single prompt, but modern AI applications are rarely that simple. Today's systems routinely involve:
- System prompts
- Conversation history
- Retrieval-Augmented Generation (RAG)
- Tool calls and external API requests
- Memory systems
- Multi-step reasoning
- Structured outputs
Every one of these influences token consumption, and most calculators simplify them too aggressively. Some rely on rough token assumptions, others don't account for how different models tokenize text, and many estimate a single prompt rather than an entire workflow. As agents get more sophisticated, those gaps get wider — the estimate looks reasonable during planning, and the real-world bill tells a different story.
The harder problem hides inside one deceptively simple question: how many tokens will your application actually use? A prompt that looks tiny in development can balloon in production once history, retrieved context, and system instructions are bundled into every call. On top of that, different providers use different tokenizers, so the same text can produce different token counts depending on whether you're on OpenAI, Anthropic, or Google. An estimate that's accurate for one model can be off for another. The issue usually isn't the price per token — it's that the token count was wrong from the start.
A Concrete Example: The Same Text, Different Token Counts
Here's the part most calculators skip. Take a single, ordinary sentence:
"Estimate how many tokens your AI agent will use before you ship it to production."
That's 13 words and 79 characters. As a rough rule of thumb, English text runs about 4 characters per token, which would suggest ~20 tokens. But the actual count depends on the tokenizer:
| Tokenizer (example) | Approx. tokens for the sentence |
|---|---|
OpenAI o200k_base (GPT-4o) | ~16 |
OpenAI cl100k_base (GPT-3.5/4) | ~17 |
| Anthropic / Google (different schemes) | ~15–19 |
The differences look trivial at the level of one sentence. They are not trivial at scale. If your app processes that sentence — or its real-world equivalent of thousands of characters of context — across millions of calls a month, a 10–15% tokenizer difference becomes a 10–15% swing on your entire bill. (Always verify against the current tokenizer and pricing page for whichever model you actually deploy; the numbers above are illustrative.)
Forecasting a Whole Workflow, Not a Prompt
Now scale that up to a real product. Imagine an AI-powered startup growth assistant that reviews landing pages, searches the web, analyzes competitors, identifies SEO opportunities, and generates recommendations. Forecasting its cost seems straightforward — until you break down a single interaction:
| Component | Estimated Tokens |
|---|---|
| System Prompt | 500 |
| User Input | 300 |
| Retrieved Context | 1,200 |
| Tool Outputs | 500 |
| Final Response | 700 |
| Total | 3,200 |
Now imagine that interaction happening thousands of times a month. A relatively small error in token estimation — say, underestimating retrieved context by 30% — compounds into a significant gap in projected costs. This is the question traditional calculators don't answer. They tell you "what will this prompt cost?" when the question that actually matters is "what will this product cost?"
Those are very different problems. A production AI system doesn't run as a single prompt; it runs workflows, calls tools, retrieves information, serves real users, and scales. Most calculators stop at the token math and never touch the architectural decisions that drive the real bill — and that's exactly where things get interesting.
How PitCrew Forecasts Costs Before You Build
One tool taking a different angle here is PitCrew, which is built to forecast AI costs before development begins. Instead of asking for token counts, code, or implementation details, it starts with a plain-English description of what you're building. From there it asks about:
- The type of agent
- Usage expectations
- Models under consideration
- Tool usage
- Operational assumptions
It then generates a cost forecast and optimization plan. What I found interesting is that the flow is designed around how founders think about products rather than how engineers think about tokens — it asks "what are you building?" rather than "how many tokens will your prompt consume?"
Worth noting: a forecast is only as good as the assumptions you feed it, so treat any pre-build estimate (PitCrew's included) as a planning aid to validate against real usage once you ship, not a guarantee. It's a useful starting point precisely because it forces you to make those assumptions explicit early.
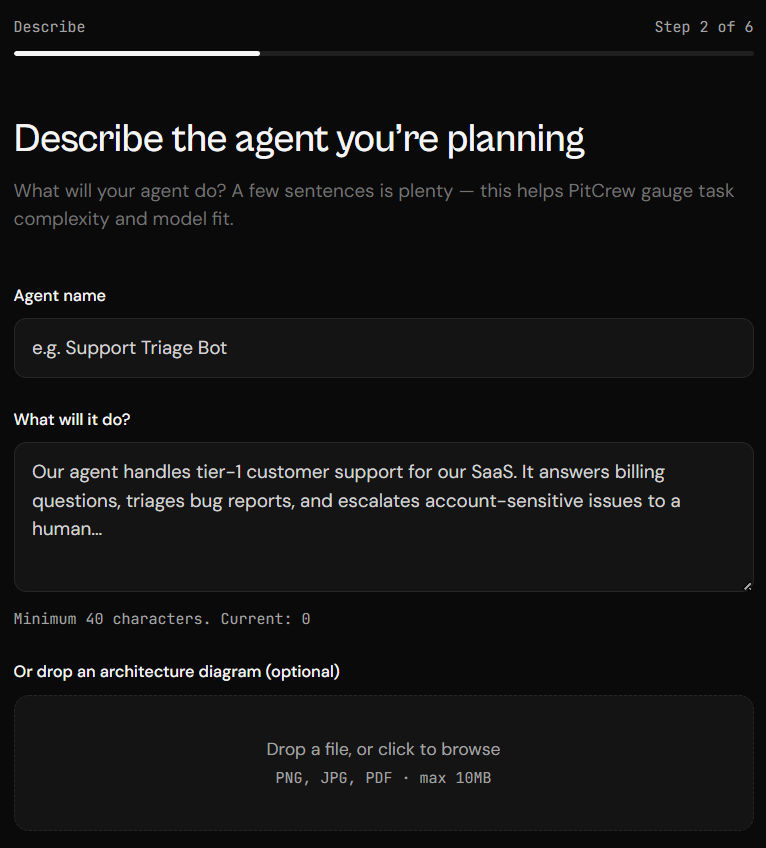
The workflow begins by understanding the agent itself. You describe the problem it solves, and PitCrew uses that to estimate complexity, model fit, and potential operating costs.
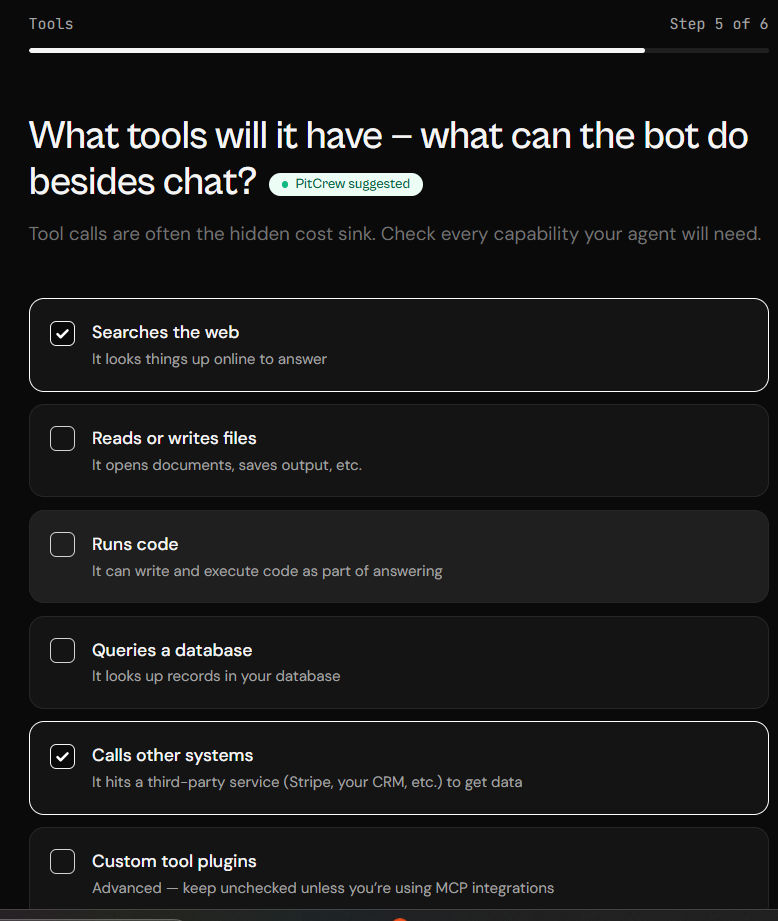
After gathering information about the workflow, PitCrew asks about the tools and capabilities your agent will use. This matters because web searches, API calls, memory systems, and external integrations can significantly affect operating costs.
Real Example: Forecasting a Startup Growth Agent
To see how AI cost forecasting differs from traditional calculators, I tested PitCrew using a startup growth agent concept. The agent would:
- Analyze landing pages
- Identify conversion issues
- Suggest SEO improvements
- Compare competitors
- Recommend launch directories
- Generate growth strategies
Instead of estimating tokens manually, I described the product and answered questions about expected usage and capabilities.
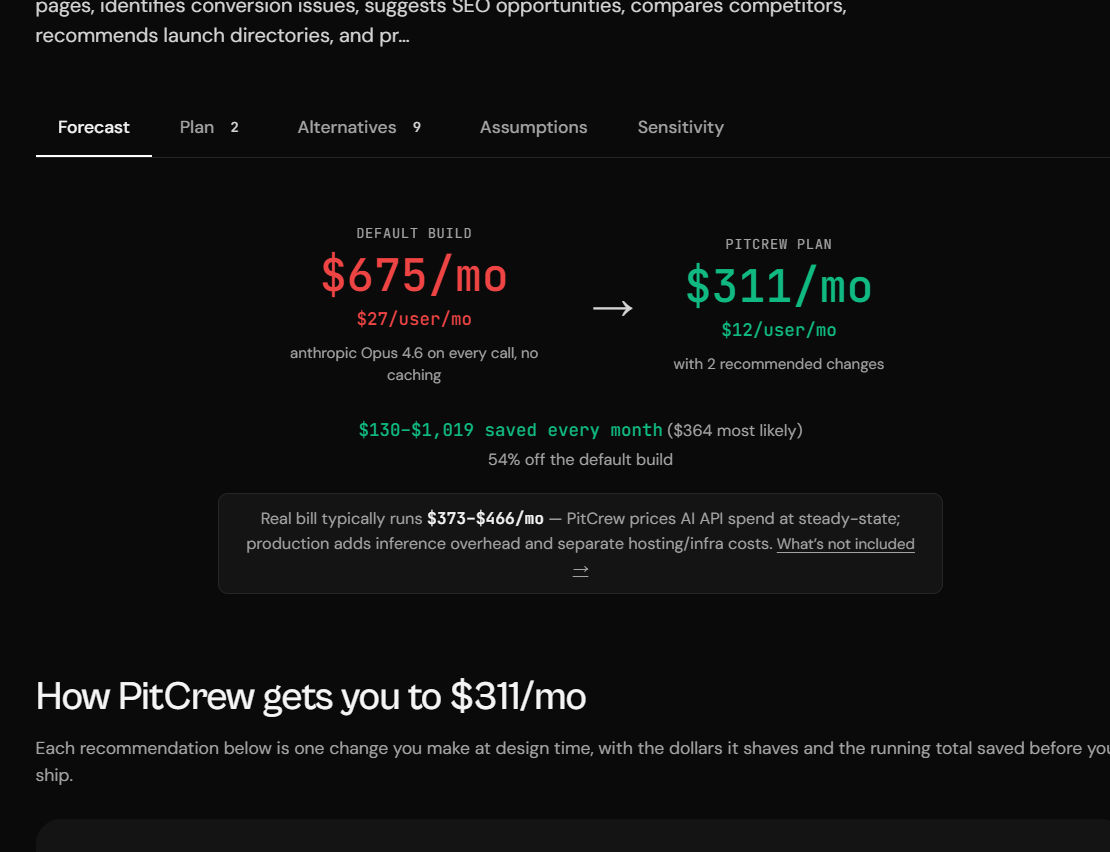
The resulting forecast estimated a monthly operating cost of approximately $675 per month based on the original architecture assumptions. More importantly, PitCrew didn't stop at a number — it analyzed the workflow and flagged opportunities to reduce costs before any development had started.
Finding Cost Savings Before Deployment
One of the most interesting parts of the report was the optimization plan. Rather than just showing a projected bill, PitCrew explained where the costs were coming from and suggested practical changes that could reduce spending without significantly affecting the intended functionality.
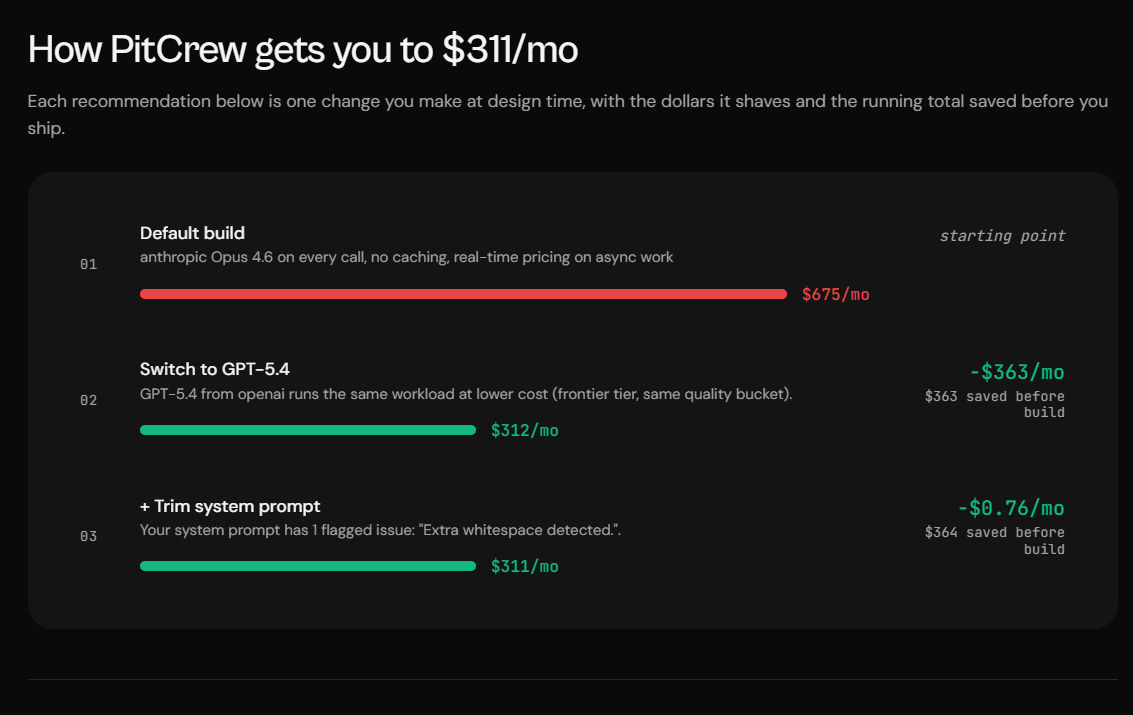
In this case, the platform identified changes that brought the projected monthly cost from roughly $675/month down to $311/month — an estimated saving of around 54%. For founders building AI products, recommendations like these can be more valuable than the forecast itself, because they shape architecture decisions before development resources are committed.
Comparing AI Models Before You Commit
Choosing a model is often one of the hardest decisions when building AI products. I've compared OpenAI, Anthropic, Gemini, DeepSeek, Groq, and OpenRouter across different projects, and pricing pages rarely tell the whole story — the same application can have very different operating costs depending on the model you choose.
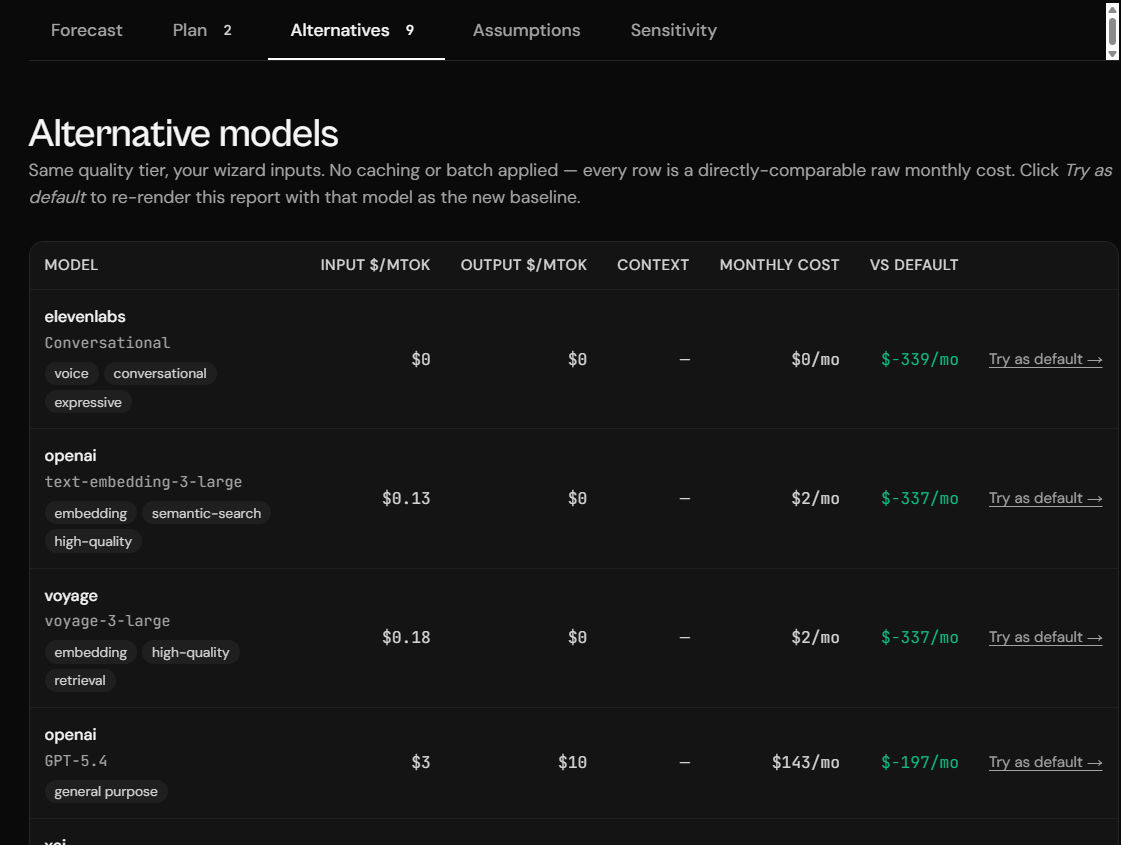
PitCrew compares alternative models against the same projected workload, making it easier to see how different model choices affect monthly cost. Instead of manually estimating costs across providers, you can evaluate alternatives against a consistent set of assumptions and find the option that strikes the best balance between quality and cost.
Frequently Asked Questions
An AI Token Cost Calculator helps estimate how much you'll spend when using AI models based on token consumption. By analyzing token usage and model pricing, these tools provide projected costs before deployment
Many AI cost estimates rely on simplified assumptions. Real-world AI applications often include conversation history, system prompts, tool calls, retrieved context, and varying response lengths, all of which can significantly affect token usage and final costs
Yes. OpenAI, Anthropic, Google, and other providers use different tokenizers. The same input can produce different token counts depending on the model, which is one reason cost estimates can vary across providers
The most reliable approach is to forecast costs using your expected workflow, model selection, tool usage, and traffic assumptions. Tools like PitCrew are designed specifically to estimate AI agent costs before development begins
The biggest cost drivers are usually token consumption, model selection, usage volume, context size, tool calls, retrieval systems, and response length. Even small changes in these areas can significantly impact monthly expenses
Yes. Based on the projected workload, PitCrew can compare alternative models and identify opportunities to reduce costs while maintaining a similar quality level for the intended use case
Featured on ProductArena
The products mentioned in this article are quality, early-stage products featured on ProductArena. We highlight promising tools while they're still in their early days, so you can be among the first to discover and use them.